Seed Audio 1.0

Seed Audio 1.0 gera a cena sonora
Descreva a cena que você quer e o seed audio 1.0 gera todo o áudio em uma passagem. Ele monta diálogo de várias vozes, trilha de fundo e ambiência a partir dessa única descrição. Funciona como um gerador Seed Audio completo, não como uma conversão de texto em fala comum, então podcasts, anúncios, jogos e vídeos saem com som pronto.
Quem recorre ao Seed Audio 1.0

Produtor de Podcast
Você precisa de uma abertura, leituras de anúncio e camas musicais sem reservar estúdio. O seed audio 1.0 gera uma voz apresentadora, música e transições a partir de um roteiro, então o episódio ganha som em uma passagem. Quando um bloco pede outro tom, você define no prompt e gera de novo.

Criador de Vídeo Curto
Seus clipes saem todo dia e cada um precisa de narração e uma base de fundo rápido. O modelo sonoriza o corte inteiro a partir de um prompt, então o reel fica pronto antes da trend passar. Nomeie o ritmo e o clima para uma leitura mais próxima.

Designer de Áudio de Jogos
Você prototipa cenas que pedem diálogo, ambiência e camadas de efeito antes da gravação final. O modelo devolve uma cama sonora completa e falas de várias personagens a partir de uma descrição, então a fase já roda com áudio cedo. Notas claras de papel deixam as vozes mais firmes.
O que o Seed Audio 1.0 cria
Aqui está o que o gerador Seed Audio produz depois que você descreve a cena.

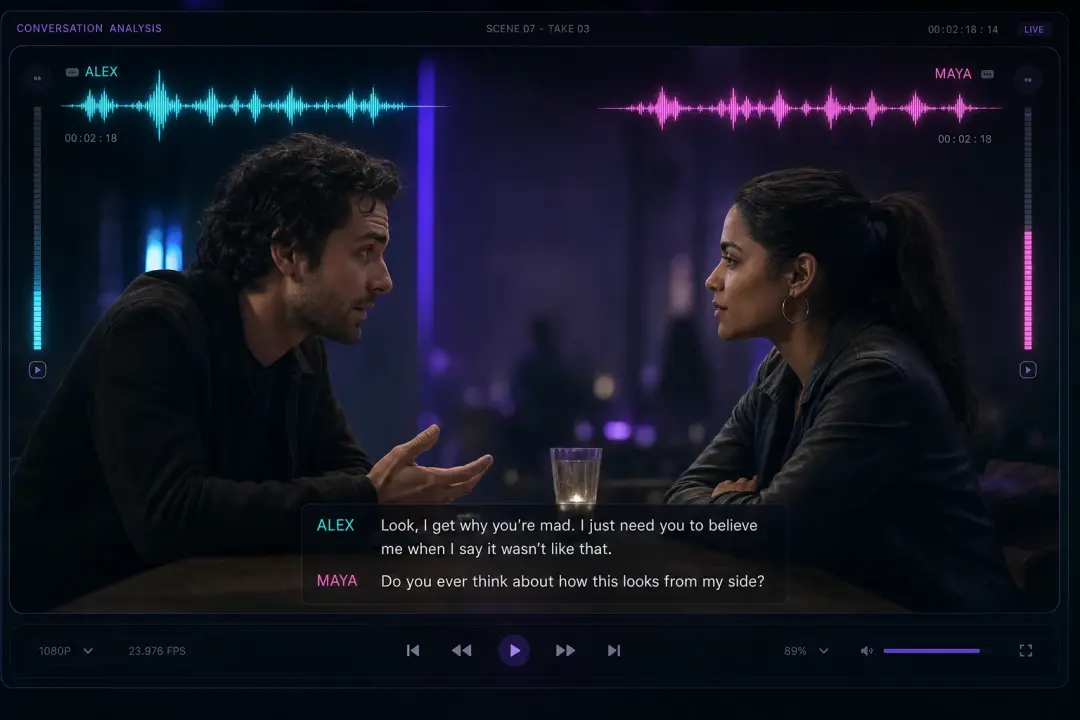
Cena de Diálogo com Várias Vozes
Escreva um roteiro curto com dois ou três locutores e o seed audio 1.0 dá voz a cada papel com uma leitura distinta em uma passagem. Atribua uma voz por personagem e depois confira o tempo. Falas sobrepostas encaixam melhor quando você marca quem fala primeiro.
Intro de Podcast com Música
Descreva o programa e o modelo monta uma abertura falada sobre uma cama musical original que combina com o gênero. Defina a duração e a energia no prompt. Um gênero nomeado rende uma cama mais limpa que um clima vago.

Ambiência e Efeitos de Jogo
Descreva um local como um mercado ou uma caverna e o modelo devolve ambiência mais as camadas de efeito que vendem o espaço. A base fica sob o diálogo sem encobrir a fala. Um cenário específico supera um genérico.

Voz de Referência Clonada
Dê uma referência curta e limpa e o modelo lê novas linhas com essa mesma voz na peça inteira. Mantenha a amostra clara para o clone segurar o tom. Você confirma a leitura antes de exportar.
Seed Audio 1.0 vs conversão de texto em fala
Veja como o modelo se compara às formas mais antigas de conseguir áudio.
Cena Completa vs Narração Chapada
A conversão de texto em fala comum lê suas palavras em uma voz só, sem música nem ambiência. O modelo gera diálogo, trilha e efeitos juntos como uma cena única. Quando o briefing muda, você reescreve o prompt em vez de regravar.
Um Prompt vs Muitas Fontes
Bancos de áudio fazem você buscar, ouvir e licenciar cada faixa e efeito por conta própria. O modelo devolve voz, música e som a partir de uma descrição só. Você ainda ajusta a mixagem, mas o ponto de partida já vem montado.
Sua Voz vs Leituras Genéricas
Uma narração de banco soa como todo mundo que comprou o mesmo arquivo. O modelo clona uma referência ou usa um preset para a leitura combinar com o seu projeto. Se a referência tem ruído, o clone perde detalhe.
Dúvidas de som que criadores fazem

Comece pelo gerador Seed Audio
Descreva uma cena, gere as vozes, a música e os efeitos e ouça a mixagem em minutos. A VideoAI roda o modelo para que podcasts, vídeos e jogos ganhem áudio pronto a partir de um prompt.
Começar