Seed Audio 1.0

seed audio 1.0 生成完整的聲音場景
描述你想要的場景,seed audio 1.0 就一次把整段音訊生成出來。它會把多角色對白、背景配樂和環境音疊在同一段描述之上。它是一個完整的 seed audio 生成器,而不是普通的語音合成,所以播客、廣告、遊戲和影片都能拿到成形的聲音。
誰會用到 seed audio 1.0

Podcast 製作人
你需要片頭、口播廣告和段落墊樂,卻不想每次都進錄音室。seed audio 1.0 從一份腳本生成主持人聲、音樂和轉場,一集的聲音一次就到位。某個段落想換個語氣,就在提示裡設定,再重新生成。

短影音創作者
你的短片每天更新,每一支都得快速配上旁白和背景墊樂。seed audio 1.0 用一句提示就把整段剪輯配好,熱度還沒退,成品就準備好了。把節奏和情緒講清楚,貼合度會更高。

遊戲音效設計師
你在正式錄音前,要先把帶有對白、環境音和音效層的場景做出原型。seed audio 1.0 從一段描述回傳完整的聲音床和多角色台詞,關卡很早就能帶著聲音試玩。角色設定寫得清楚,角色聲線會更穩定。
seed audio 1.0 能做出什麼
描述好場景之後,這個 seed audio 生成器 能產出這些東西。

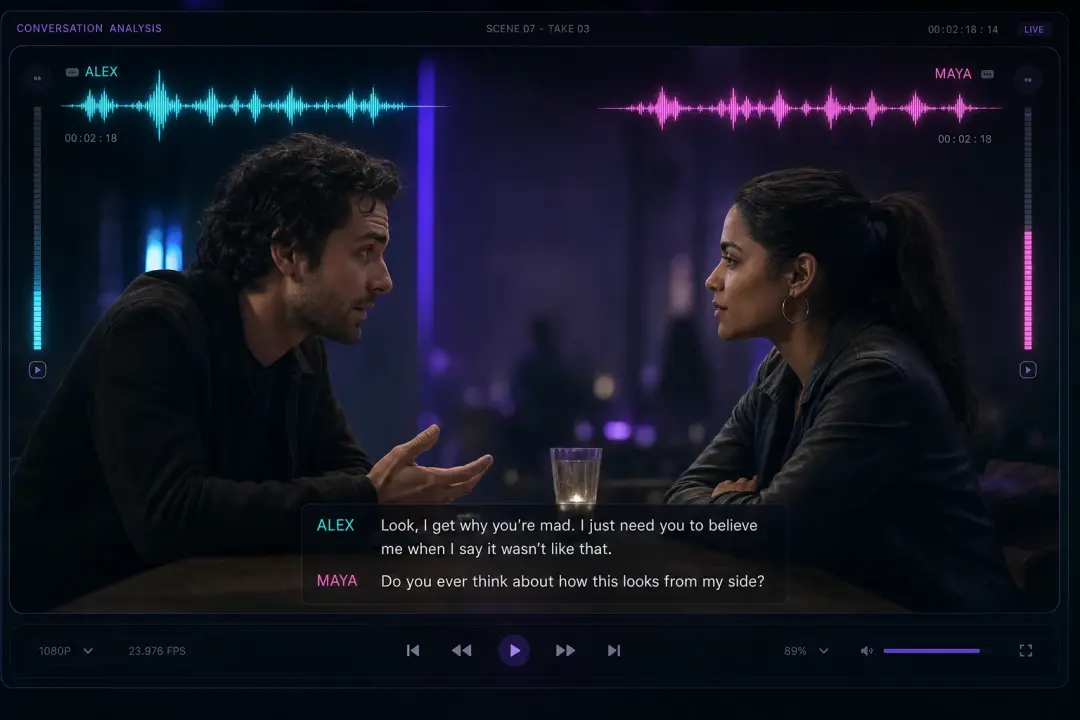
多角色對白場景
寫一段兩三個人講話的短腳本,seed audio 1.0 一次就為每個角色配上穩定又有辨識度的語氣。幫每個角色指定一個聲音,再對照分鏡檢查時間點。台詞有重疊時,先標出誰先開口,效果最好。
Podcast 片頭加配樂
描述你的節目,seed audio 1.0 就在一段原創音樂床上鋪出口白片頭,風格也對得上類型。在提示裡設定長度和能量。指名曲風,會比模糊的情緒得到更乾淨的墊樂。

遊戲環境音與音效
描述一個地點,像市集或洞窟,seed audio 1.0 會回傳環境音,再加上撐起空間感的音效層。這層墊在對白底下卻不會蓋掉人聲。場景講得具體,會比籠統的描述更到位。

克隆參考音色
給一小段乾淨的參考音,seed audio 1.0 就用同一個聲音在整段作品裡念新台詞。樣本保持清楚,克隆出來的音色才守得住。匯出前你要先確認一次唸法。
seed audio 1.0 與語音合成
來看看這個模型和以前取得音訊的老方法差在哪。
完整場景 vs 語音合成
普通的語音合成只用一個聲音把你的字唸出來,沒有音樂也沒有環境音。seed audio 1.0 把對白、配樂和音效當成同一個場景一起生成。需求變了,你改寫提示就好,不必重新錄。
一句提示 vs 逐一找素材
素材庫要你一段一段搜尋、試聽、逐一授權每首音樂和每個音效。seed audio 1.0 從一段描述就回傳人聲、音樂和聲音。你還是會微調混音,但起點已經是組好的。
你的音色 vs 通用配音
通用配音聽起來跟所有買了同一個檔案的人一樣。seed audio 1.0 可以克隆一段參考,也能用內建預設,讓唸白貼合你的專案。要是參考很吵,克隆就會掉細節。
創作者最常問的聲音問題
