Seed Audio 1.0

Seed Audio 1.0 一次生成完整音频场景
描述你想要的场景,seed audio 1.0 就在一次生成里给出整段音频:多角色对白、背景配乐、氛围音和音效层层叠好。它是一个完整的 seed audio 生成器,而不是只会念稿的语音合成,所以播客、广告、游戏和短视频都能拿到成品声音。
谁在用 seed audio 1.0

播客制作人
你需要片头、口播广告和分段垫乐,却不想再约录音棚。seed audio 1.0 能从一段脚本生成主持人声、配乐和转场,一集节目一次就有了声音。某个环节想换个语气,在提示词里写清楚再重新生成即可。

短视频创作者
你的视频每天都要更新,每条都得快速配上旁白和背景垫乐。seed audio 1.0 从一句提示词就为整条成片铺好声音,趋势还没过去,片子已经能发。把节奏和情绪说清楚,匹配会更贴。

游戏音频设计师
你在正式录制前,需要先给场景搭出对白、氛围和音效层。seed audio 1.0 能从一段描述返回完整声床和多角色台词,关卡很早就能带着声音试玩。把角色设定写清楚,音色会更稳定。
seed audio 1.0 能生成什么
把场景描述清楚,这个 seed audio 生成器 就能产出下面这些成品。

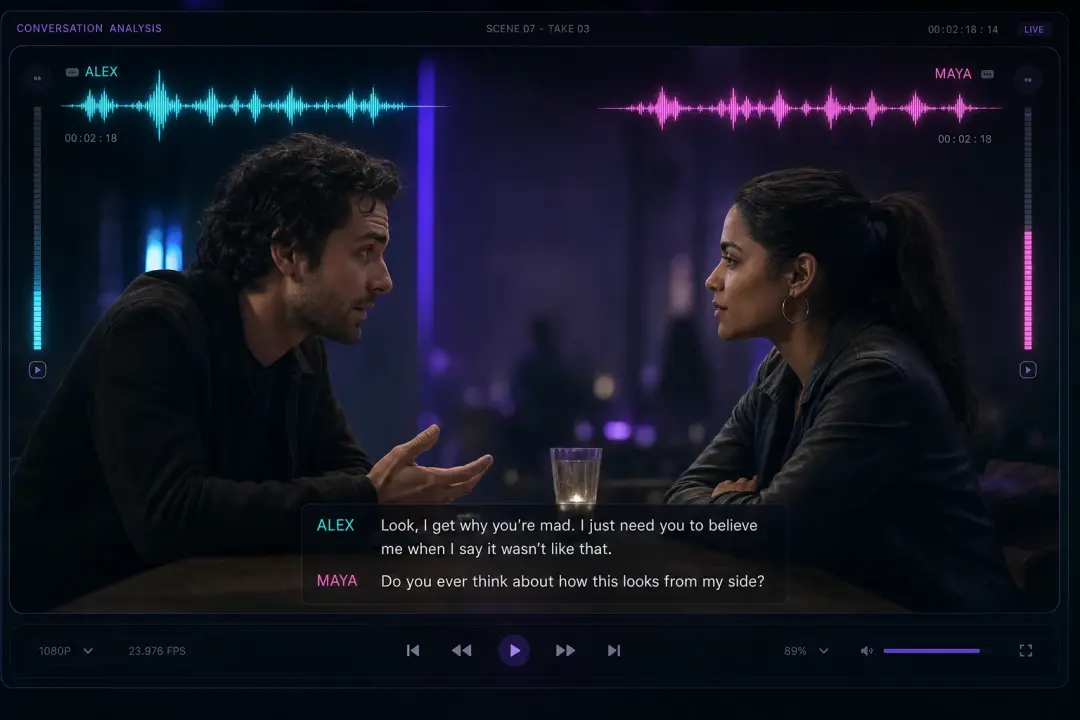
多角色对白场景
写一段有两三个说话人的短脚本,seed audio 1.0 会在一次生成里给每个角色一个稳定又有区分度的声音。先给角色分配音色,再检查时间轴。台词有重叠时,标清楚谁先开口效果最好。
播客片头加配乐
描述你的节目,seed audio 1.0 就在一段原创配乐上搭出口播片头,风格与节目类型相衬。在提示词里定好时长和情绪,写明确的音乐类型比模糊的氛围词更出彩。

游戏氛围与音效
描述一个地点,比如集市或山洞,seed audio 1.0 会返回氛围音,加上撑起空间感的音效层。声床垫在对白之下,不会盖住人声。地点写得具体,效果胜过泛泛而谈。

克隆参考音色
给一段简短干净的参考音频,seed audio 1.0 就能用同一个音色朗读整段新台词。样本保持清晰,克隆出来的音色才稳。导出前你可以先确认这段朗读。
seed audio 1.0 和语音合成有何不同
下面看看这个模型和以往获取音频的方式相比有什么不同。
完整场景 vs 平铺旁白
普通的语音合成只会用一个声音把文字念出来,没有音乐也没有氛围。seed audio 1.0 把对白、配乐和音效当成一个场景一起生成。需求变了,你改提示词就行,不用重新录制。
一句提示 vs 四处找素材
素材库要你一条条地搜索、试听,再逐个授权每段音乐和音效。seed audio 1.0 从一句描述就返回人声、音乐和音效。你仍然可以再调混音,但起点已经拼好了。
你的音色 vs 千篇一律配音
买来的配音听起来和所有买了同一个文件的人一样。seed audio 1.0 可以克隆一段参考,也可以用预设音色,让朗读贴合你的项目。参考音频有噪声时,克隆会丢掉细节。
关于 seed audio 1.0 的常见问题

启动你的 seed audio 生成器
描述一个场景,生成人声、音乐和音效,几分钟内就能听到混音。VideoAI 运行 seed audio 1.0,让播客、视频和游戏都能从一句提示词得到成品音频。
免费开始