Seed Audio 1.0

seed audio 1.0 이 만드는 오디오 장면
원하는 장면을 설명하면 seed audio 1.0 이 음성과 다중 캐릭터 대사, 오리지널 음악, 환경음, 효과음을 단 한 번의 생성으로 쌓아 올립니다. 단순한 음성 합성이 아니라 완결된 오디오를 만드는 seed audio 생성기이기 때문에, 팟캐스트든 숏폼이든 게임이든 바로 쓸 수 있는 사운드를 얻습니다.
seed audio 1.0 을 찾는 크리에이터

팟캐스트 제작자
스튜디오를 잡지 않아도 인트로와 광고 멘트, 코너 배경음이 필요합니다. seed audio 1.0 은 대본에서 진행자 목소리와 음악, 전환음을 한 번에 만들어 한 편의 사운드를 채웁니다. 코너마다 톤이 달라야 하면 프롬프트에 적어 다시 생성하면 됩니다.

숏폼 영상 크리에이터
매일 올리는 클립마다 내레이션과 배경음이 빠르게 필요합니다. seed audio 1.0 은 프롬프트 하나로 컷 전체에 소리를 입혀, 트렌드가 지나가기 전에 릴스를 마칠 수 있습니다. 원하는 템포와 무드를 적으면 결과가 더 잘 맞습니다.

게임 오디오 디자이너
최종 녹음 전에 대사와 환경음, 효과음 레이어가 필요한 장면을 프로토타이핑합니다. seed audio 1.0 은 설명만으로 다중 캐릭터 대사와 사운드 베드를 돌려줘 레벨을 일찍 소리와 함께 플레이합니다. 배역 설명이 분명할수록 캐릭터 목소리가 안정적입니다.
seed audio 1.0 로 만드는 결과물
장면을 설명하고 나면 seed audio 생성기가 실제로 만들어 내는 결과물입니다.

다중 캐릭터 대화 장면
두세 명이 나오는 짧은 스크립트를 쓰면 seed audio 1.0 이 배역마다 또렷하고 안정적인 목소리를 한 번에 입힙니다. 캐릭터별로 보이스를 지정하고 타이밍을 확인하세요. 대사가 겹칠 때는 누가 먼저 말하는지 표시하면 자연스럽습니다.
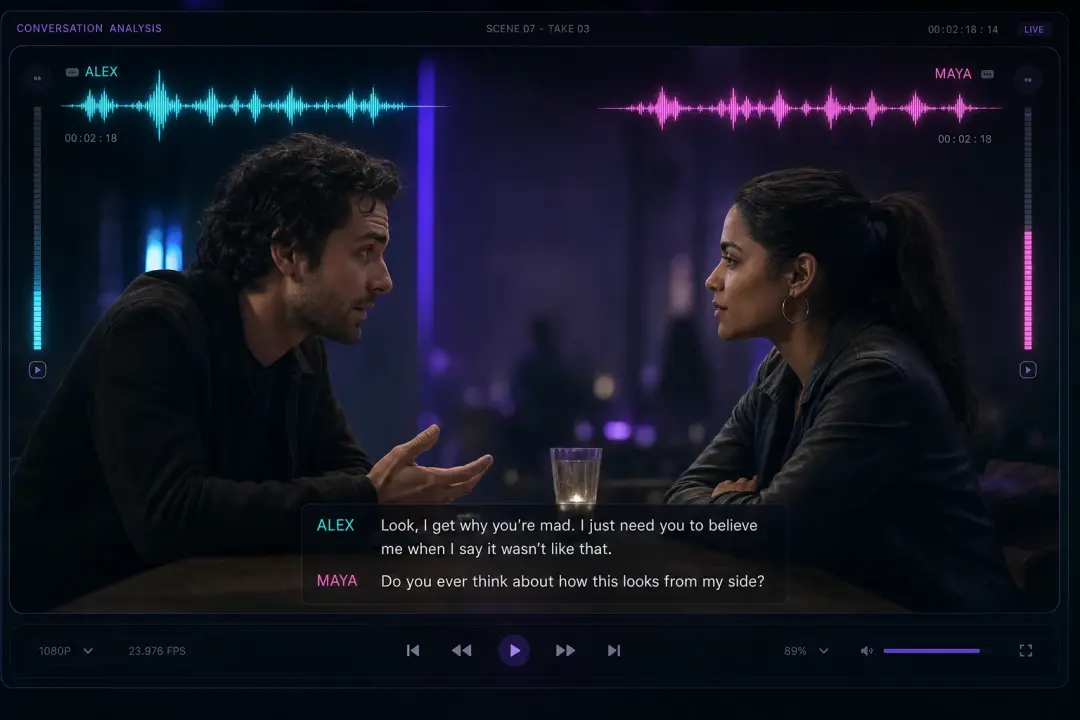
팟캐스트 인트로와 음악
쇼를 설명하면 seed audio 1.0 이 장르에 맞는 오리지널 음악 위에 낭독 인트로를 얹어 줍니다. 길이와 에너지는 프롬프트에서 정합니다. 막연한 무드보다 장르를 콕 집으면 훨씬 깔끔한 베드가 나옵니다.

게임 환경음과 효과음
시장이나 동굴 같은 장소를 설명하면 seed audio 1.0 이 공간을 살리는 환경음과 효과음 레이어를 돌려줍니다. 이 베드는 대사를 가리지 않고 아래에 깔립니다. 두루뭉술한 장소보다 구체적인 설정이 결과가 좋습니다.

참조 음성 클론
짧고 깨끗한 참조 음성을 주면 seed audio 1.0 이 같은 목소리로 작품 전체의 새 대사를 읽습니다. 샘플을 선명하게 유지해야 클론이 톤을 지킵니다. 내보내기 전에 낭독을 한 번 확인하세요.
seed audio 1.0 vs 음성 합성
예전처럼 오디오를 구하던 방식과 이 모델이 어떻게 다른지 정리했습니다.
완성된 장면 vs 밋밋한 낭독
일반적인 음성 합성은 한 가지 목소리로 글자만 읽고 음악이나 환경음은 없습니다. seed audio 1.0 은 대사와 스코어, 효과음을 하나의 장면으로 함께 생성합니다. 브리프가 바뀌면 다시 녹음하는 대신 프롬프트를 고쳐 씁니다.
프롬프트 하나 vs 여러 소재 검색
스톡 라이브러리는 트랙과 효과음을 하나씩 찾고 미리 듣고 라이선스를 걸어야 합니다. seed audio 1.0 은 하나의 설명에서 음성과 음악, 사운드를 함께 돌려줍니다. 믹스는 다듬더라도 출발점이 이미 짜여 있습니다.
내 목소리 vs 흔한 낭독
스톡 성우는 같은 파일을 산 모두와 똑같이 들립니다. seed audio 1.0 은 참조를 복제하거나 프리셋을 써서 프로젝트에 맞는 낭독을 만듭니다. 대신 참조가 지저분하면 클론이 디테일을 잃습니다.
크리에이터가 자주 묻는 사운드 질문

지금 오디오 장면을 생성해 보세요
원하는 장면을 설명하면 seed audio 1.0 이 음성과 음악, 효과음을 몇 분 만에 하나의 믹스로 들려줍니다. VideoAI가 seed audio 생성기를 돌려 팟캐스트와 숏폼, 게임 모두 완성된 오디오를 얻습니다.
시작하기